
GALGO — Golden Age Literature Glossary Online — is a platform for textual annotation and collaborative reading. Initial restricted to a corpus of Golden Age Spanish language texts, the latest version supports a wide range of texts and languages.
Most scholarly glossaries are static lists. GALGO is something more: a structured research environment for tracing how specific words function across an entire literary corpus, grounded in M.A.K. Halliday's social semiotic theory of language.
The premise is that a keyword from Golden Age Spanish literature isn't just a word with a translation - it's a reflection of the cultural environment, the social structure, and the linguistic system that produced it. GALGO aims makes that depth navigable, especially to students in guided learning. Often readers, even with significant familiarity with the modern language, miss the nuance of these terms in archaic contexts.
The Problem
Readers approaching early modern Spanish literary works encounter a vocabulary that is simultaneously archaic, idiosyncratic, and culturally dense. Existing reference tools offer definitions. What they don't offer is context: how a term is used across a single work, how that usage shifts across multiple works, what the word reveals about the society that produced it.
Scholars Nuria Alonso García and Alison Caplan built the intellectual framework for GALGO. They approached me in 2012 to see if I could build an web application.
What We Built
GALGO is a searchable, multilayered glossary database with a custom research interface. The core capability is comparative: a user can look up a keyword and trace not just its definition, but its usage patterns — within a single text, across the corpus, and across historical periods.
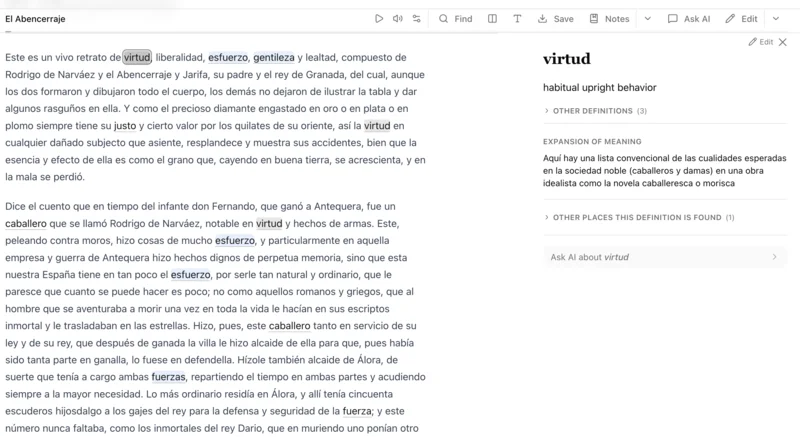
The initial application was build on a Laravel API with a backbone.js frontend. By making the application API driven, we could create a flexible frontend that would allow us to mutate the text in the browser - injecting and transforming the DOM as needed. We encoded the texts as TEI XML and wrote an algorithm to parse and index the texts into key words. We then created a glossary system that would allow experts to define key terms, and the various forms of the terms to make them identifiable in the text. Because the texts were indexed with robust positional data, we could create associations between a term and a "context" - a word in position in a text.
In 2026, Alison and Nuria reached back out to me. The app was still in active use, remarkable considering that we had not significantly extended it in over 10 years. The institution hosting the application could no longer continue to host it. To support it going forward, we needed a new host, technology stack, and we needed to make it self-serviceable.
The Future Version
We are currently road testing version 2.0. Completely rebuilt, ground-up, it has now become a much more powerful tool. Using NextJS and Postgres, we could preserve much of the headless architecture, but build powerful, modern tools for text management, search, accessibility, and cross text term linking.

There are three features I'm especially proud of -
- Multitenentcy - The system now supports multiple projects, with their own corpus, glossary and user management. The system supports a large array of languages with full indexing, stemming and search. Role based access control lets professors build a glossary, control who can access it, and annotate both key context terms and general context. Students annotate the same text as they read, with those annotations only available to the student and professor.
- Learning Mode - Professors can enable this mode for a text. Students can now suggest definitions for a term in context. Then the professor can review in class with the students, using the suggested ideas to guide the conversation, and ultimately arrive at the contextual meaning.
- Effortless Management - A elegant UI makes it easy for professors to upload and validate texts - supporting a wide range of formats. Seamless backend transformation silently cleans the uploaded text, ensuring that its well structured, index, and visually clear. Professors can search the text for terms or phrases, creating terms, variations, and contexts right inline as they read.